This blog post was written by Laura Moberg, a graduate student in the Dual Master of Archival Studies and Master of Library and Information Studies program at the UBC School of Information.
Introduction
As a project for the course ARST 556L/LIBR 514L: Metadata in the fall of 2021, I worked with the UBC Library Digitization Centre to perform quality control and metadata cleanup for the UBC Institute of Fisheries Field Records (UBC IFFR) collection (see Figure 1). This is a digitized collection available on UBC Library’s Open Collections which includes over 11,000 field records describing fish specimens held in the Beaty Biodiversity Museum’s Fish Collection. The digital collection’s metadata needed to be processed before the collection could be migrated from the Digitization Centre’s legacy content management system, CONTENTdm, to the new Digital Asset Management System (DAMS), DSpace. The main objective of my project was to ensure that the UBC IFFR collection’s metadata aligned with the Digitization Centre’s metadata standards. Most importantly, Digital Identifiers needed to be assigned to the items in order to match the metadata to the digital files in the DAMS migration process.
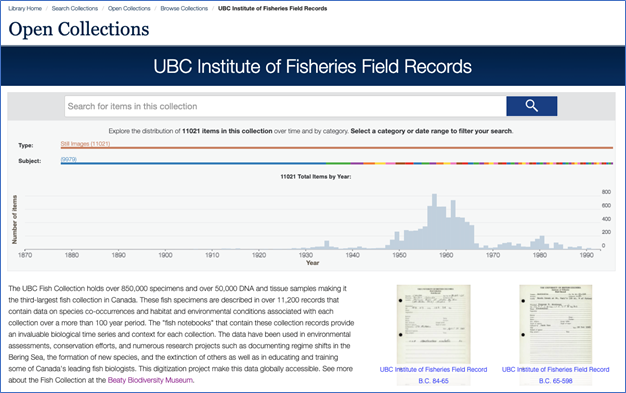
Figure 1: Homepage of the UBC Institute of Fisheries Field Records collection on Open Collections.
Steps
- Reviewing the Digitization Centre’s Metadata Manual
As the goal of this project was to align the UBC IFFR collection with established metadata standards, my first step was to review and become familiar with the Digitization Centre’s Metadata Manual. This metadata schema includes information about which metadata fields are mandatory or optional and instructions on how to assign values for each field. The UBC IFFR collection is unique because it includes a collection-specific metadata schema with fields not used for other collections (see Figure 2). This schema maps to the template structuring the field records, which were filled out by typewriter or by hand (see Figure 3). Because so much work was put into manually transcribing these fields during the digitization process, they were preserved in the metadata cleanup.
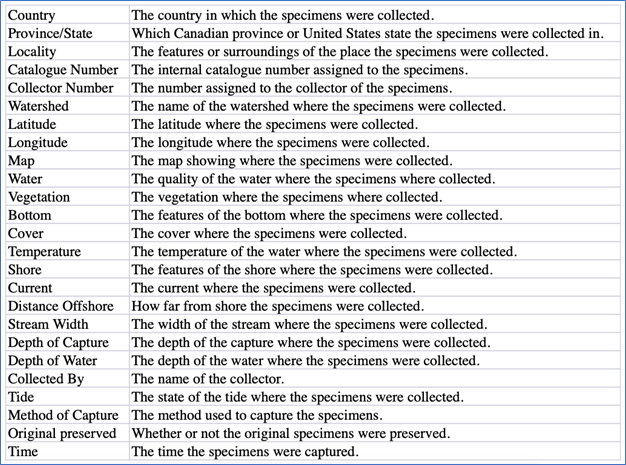
Figure 2: Metadata schema for the UBC Institute of Fisheries Field Records collection which maps to the field record template.

Figure 3: A sample UBC Institute of Fisheries field record which has been filled out by typewriter and by hand (B.C. 59-65, image cropped).
- Quality control and assigning Digital Identifiers
The next step in the project was to assign Digital Identifiers for the items. According to the Digitization Centre’s Metadata Manual (p. 24), these identifiers correspond to the file names of the digital objects (without the file extensions) and are usually based on the access identifier or call number of an item. In the case of the UBC IFFR collection, the Digital Identifiers were based on the Catalogue Numbers originally assigned by the UBC Institute of Fisheries and found on the records themselves. As an example, the field record with the Catalogue Number B.C. 61-78 has the file name/Digital Identifier bc61_078.
The process of assigning Digital Identifiers involved performing quality control (QC) on the digital objects held on the Digitization Centre’s servers and comparing these to the metadata spreadsheets (see Figure 4). I also had to address any errors which arose during the QC process, including inconsistencies or duplications within the Catalogue Number field.
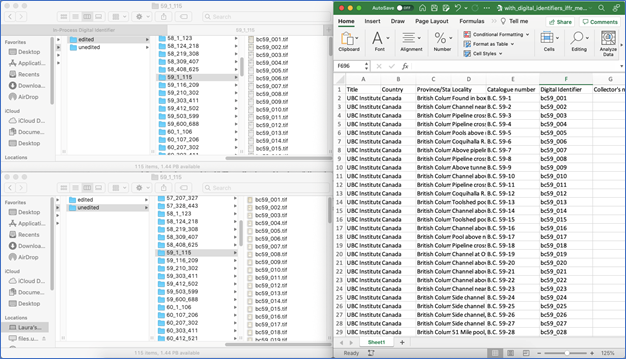
Figure 4: My QC view. On the left-hand side of my screen, I opened both the “edited” and “unedited” Digital Objects folders, which I compared to each other through spot checking. On the right-hand side of my screen, I opened the metadata spreadsheet for the year I was currently working on (here, 1959), where I would check that the names and numbers of digital files matched the spreadsheet rows, address any QC issues, and assign Digital Identifiers in a new column (column F).
- Batch updating CONTENTdm metadata using Catcher
Next, I had to update these Digital Identifiers within the item metadata on CONTENTdm. Because I needed to update over 11,000 field records, I was not going to do this one record at a time! Instead, I used the CONTENTdm Catcher web service, which supports batch edits to existing metadata fields. This involved creating a copy of the metadata spreadsheet which included only two columns––the Digital Identifier and the CONTENTdm number (a unique identifier used to match the edits with specific items)––which would be submitted to Catcher.
- Cleaning metadata with OpenRefine
Once the Digital Identifiers had been updated through Catcher and I had spot-checked to ensure that the identifiers were applied accurately, I was ready to start cleaning the metadata. To do this, I used OpenRefine, an open-source software which allows users to explore and clean large quantities of metadata. I first did a fresh export of the collection’s metadata from CONTENTdm in the form of a tab-delimited text file, which I then opened in OpenRefine (Figure 5).
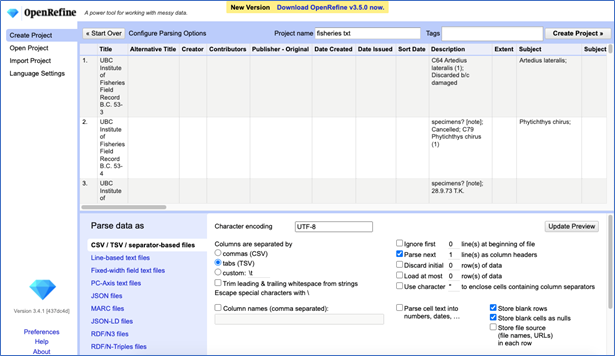
Figure 5: Creating a new project in OpenRefine.
My primary aim was to ensure that the standard metadata fields aligned with the Digitization Centre’s Metadata Manual. Using OpenRefine’s faceting functions, I ensured that the required fields were not missing values and that the values were unique in the fields where that mattered (Catalogue Number, DOI, Digital Identifier).
While I had originally intended to check the collection-specific metadata fields only briefly, I soon discovered that the practice of directly transcribing the information on the field records had to led to some pretty messy metadata (Figure 6). My supervisors and I discussed the need strike a balance between being faithful to the original record by transcribing the data directly and creating useful metadata which will best support findability and access for users. I then did some initial work of cleaning these fields through simple fixes, such as standardizing how the metadata indicates that words have been corrected or crossed out in the original record.
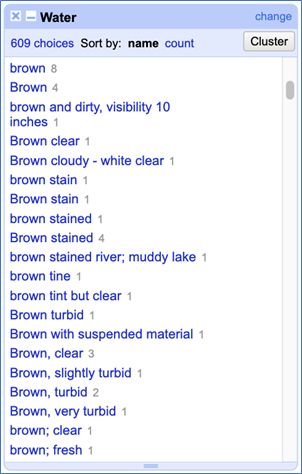
Figure 6: How many different ways can water be described as “brown”? An example of inconsistencies in the collection-specific field which described the water in which the specimens were collected.
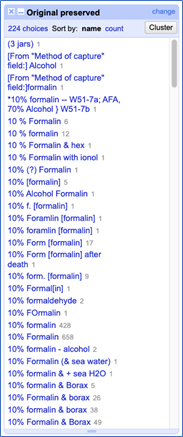
The majority of the processing work I did for the collection-specific metadata fields was in cleaning the Original Preserved field, which indicates if/how the specimens were originally preserved. I used OpenRefine’s text facet and clustering functions to standardize the spelling, spacing, punctuation, and capitalization for values in this field (Figures 7 and 8). I tried to minimize my level of interpretation by preserving certain anomalies in the data, such as an instance where the Original Preserved field indicated that the specimen was preserved at precisely 5:30 p.m.
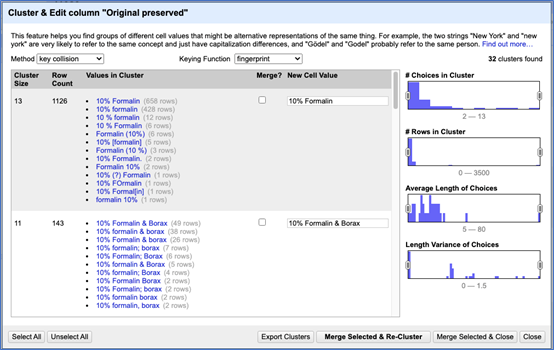
Figure 7: Using the “Cluster & Edit” tool to identify similar values which could potentially be merged
 |
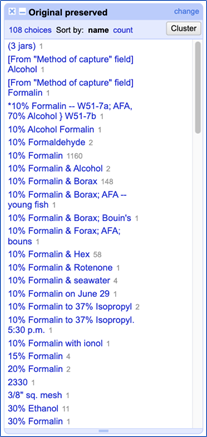 |
Figure 8: Before and after I standardized the formatting and use of capitalization in the Original Preserved field. Note that the number of choices in the text facet decreased from 224 to 108.
- Creating a Metadata Cleanup Plan
Because the amount of work required to fully clean this large dataset surpassed the scope of my class project, the metadata processing will be taken up by another student in the future. To document the metadata processing I completed and the work that still remains, I created a Metadata Cleanup Plan which highlights fields requiring particular attention and outlines decisions made around addressing errors and inconsistencies.
Conclusion
Through this project, I increased my familiarity with the Digitization Centre’s metadata standards and gained hands-on experience following digitization project workflows and processing metadata with OpenRefine. I am pleased that I was able to support the digital preservation of, and enhanced access to, this important collection. The UBC Institute of Fisheries Field Records collection’s metadata is not yet perfectly polished and may never be, due to the unique nature of the collection and its custom metadata schema. However, my contributions through this project have ensured that the collection’s standard Digitization Centre metadata fields are cleaned and in alignment with the Metadata Manual––which is still a win to me!

