This is part of a series on web archiving at the UBC Library. For all posts about web archiving, please see https://digitize.library.ubc.ca/tag/web-archiving/
From May 2017 to April 2018, as part of my work as a Digital Projects Student Librarian and a Professional Experience Student at the Digitization Centre, I worked with Larissa Ringham to develop the University of British Columbia Web Archive Collection. This post should give you a sense of why we embarked on this project, some of the major challenges associated with doing large-scale web archiving, and how we adapted or work to address those challenges.
Preserving UBC’s web-based institutional memory
In the past, a major part of UBC’s history was documented in physical records like letters and photographs. After 25 years of public access to the internet, though, many major University activities are documented within websites instead. This presents new challenges for organizations, like the Library, who have an interest in preserving content related to institutional memory. With that in mind, the Digitization Centre decided to develop a new Web Archive collection focused on websites created by UBC faculty, staff, students, administrators, and other community members.

Scaling up from small thematic collections to a large domain crawl
Since the Library started archiving websites in 2013, most collections have been created around a central theme (e.g. the 2017 BC Wildfires collection). These thematic collections have usually included less than 100 target websites (a.k.a. “seeds”), and averaged about 25GB in size. Each site is often crawled individually, and each capture is, ideally, checked by a human for quality issues like missing images.
The universe of UBC-affiliated websites exists on a much larger scale. When we initially ran week-long test crawls of the ubc.ca domain, each of them resulted in about 500GB of captured data from almost 200,000 unique hosts (e.g. library.ubc.ca). We quickly realized we needed to find a way to scale up our workflows to deal with a collection this large.
Selection, appraisal, and scoping: How do we identify and prioritize high-value “seed” websites within UBC.ca, as well as flag content to be excluded?
As of Summer 2017, when we started our test crawls on ubc.ca, Archive-It test crawls could run for a maximum of 7 days. That meant our tests would time out before capturing the full extent of the UBC domain, leaving some content undiscovered. We were also unable to find a comprehensive, regularly updated list of UBC websites that would help us make sure no important sites or subdomains were missed.
Additionally, if saved, each one of our test crawls of UBC.ca would have been large enough to use up our Archive-It storage budget for the year. Even with a one-time doubling of our storage to facilitate this project, we needed to do work to exclude large data-driven sites.
Quality Assurance: How can we identify and fix important capture issues in a scalable way
Manually clicking through and visually examining millions of captured web page would not be possible without an army of Professional Experience students with iron wrists that are miraculously immune to tendonitis.
New workflows, who dis?
After a lot of trial and error, this is how we went about our first successful capture of the ubc.ca domain.
A two-pronged approach to selection, appraisal, and scoping
First, using the results of our first few test crawls, I created a list of all of the third-level *.ubc.ca subdomains our crawler found on its journey. Some of these were immediately flagged as out of scope (e.g. canvas.ubc.ca) or defunct (e.g. wastefree.ubc.ca). The rest were classified by the type of organization or campus activity associated with the subdomain. Sites associated with major academic or administrative bodies (e.g. president.ubc.ca) were added to a list of high-priority websites, and added as a seed in Archive-It where they would be crawled individually and reviewed for issues in closer detail. For each subsequent test crawl, I ran a Python script that compared the results with our master subdomain list, flagging any new third-level subdomains for assessment.
Second, I consulted lists of UBC websites that we felt could reflect their level of usage and/or value for institutional memory. While it’s not always comprehensive or up-to-date, UBC does have an existing website directory. It’s especially helpful for identifying high-priority that aren’t a third-level *.ubc.ca subdomain, and for double-checking we’re capturing the websites for all major academic and governing bodies. In addition to that, we used a tool in Wolfram Alpha to get a list of the most-visited *.ubc.ca subdomains. This list helped us identify commonly encountered subdomains that exist for functional reasons rather than for hosting content (e.g. authentication.ubc.ca).
Archive-It’s selection and appraisal tracking capabilities are limited, so we export data from the service and consolidate it with our appraisal tracking in this spreadsheet full of V-lookup horrors.
More sustainable, targeted quality assurance
Following our existing QA workflow, I started by manually examining captures of our high-priority seeds for problems like missing images. This time, though, I carefully tracked the issues I encountered and the scoping rules we added to fix them. Pretty quickly, patterns emerged that allowed me to start addressing capture issues in bulk.
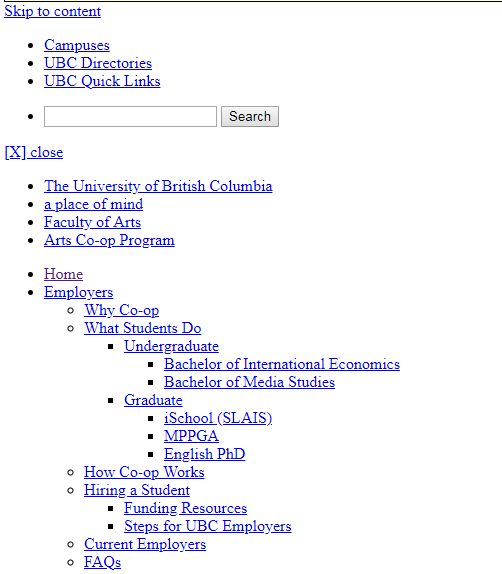
An initial capture of artscoop.ubc.ca with missing look and feel files
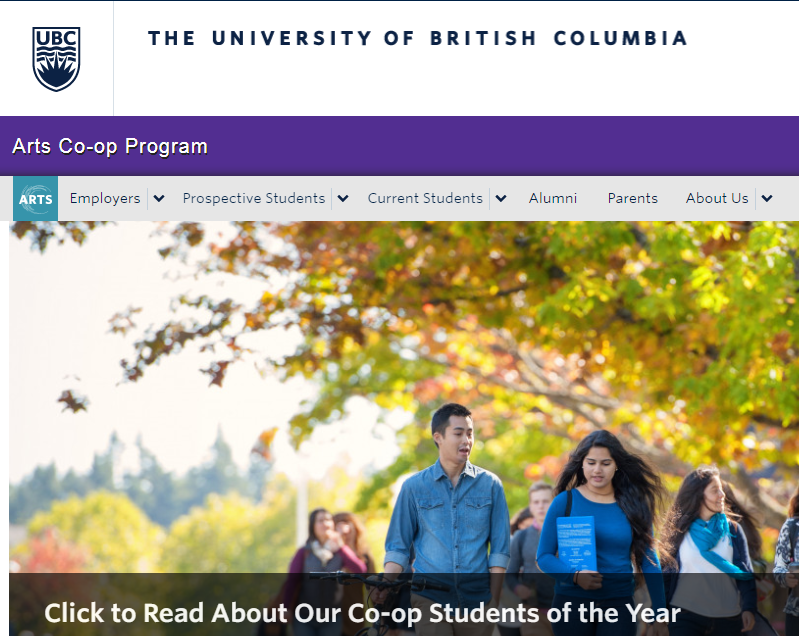
The live Arts Co-op website, featuring look and feel files and image assets.
For example, captures of WordPress sites using the UBC Common Look and Feel were all missing similar CSS files. Once I found a set of rules that fixed the problem on one impacted site, it could be set it at the collection level where it would apply to all affected sites. That includes those that aren’t considered high-enough priority to check manually, where we otherwise might be unaware there was an issue.
The results and next steps
As of today, the Library has captured and made 164 UBC websites publicly available in its Archive-It collection. These captures add up to over 700GB of data! This number continues to grow thanks to regularly-scheduled re-crawls of important sites like the Academic Calendar (crawled quarterly) and the main University domain at www.ubc.ca (crawled monthly). Next will be to establish regular crawl schedules for other high-priority sites, bearing in mind how other web archiving projects impact our crawl budget.
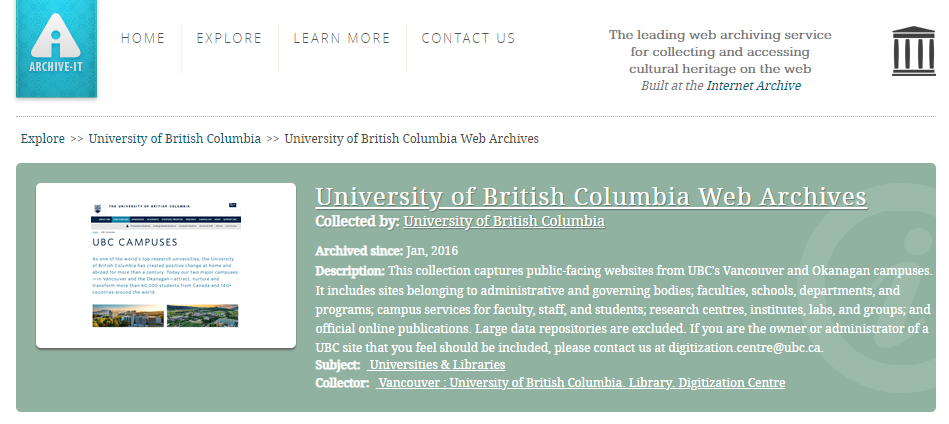
Our internal list of “seeds” also includes an additional 397 UBC websites that are sitting at various stages of the web-archiving process. Many of these have already been crawled, and the captures will be made available on the Archive-It collection page after some additional quality assurance and description work.
Get in touch
Are you the owner of a UBC-affiliated website that you think should be preserved? Read more about our Web Archiving Work, or get in touch with us at digitization.centre@ubc.ca.

